간단한 예측을 해보자!! (2)
김승우 책임
간단한 예측을 해보자!!(Titanic 생존자 예측) (2)
1편까지 EDA를 진행하였습니다. 이번 편에서는 모델링을 하고 직접 예측을 해보도록 하겠습니다.
1. Modeling
- 예측엔 Scikit Learn Library를 씁니다.
# scikit learn import
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from xgboost import XGBClassifier, plot_importance
# train set, validation set 구별을 위한 kfold 지정
kfold = KFold(n_split=5, random_state=1, shuffle=True)
-
6개 모델로 예측을 진행하도록 하겠습니다.
-
Gaussian Naive Bayes
m1_nb = GaussianNB() accuracy = np.mean(cross_val_score(m2_log, train_imputed, Survival, scoring="accuracy", cv=kfold)) -
Logistic Regression
m2_log = LogisticRegression(solver='newton-cg') accuracy = np.mean(cross_val_score(m2_log, train_imputed, Survival, scoring="accuracy", cv=kfold)) -
k-Nearest Neighbors(kNN)
m3_knn_5 = KNeighborsClassifier(n_neighbors = 5) m3_knn_10 = KNeighborsClassifier(n_neighbors = 10) m3_knn_30 = KNeighborsClassifier(n_neighbors = 30) accuracy = np.max([np.mean(cross_val_score(m3_knn_5, train_imputed, Survival, scoring="accuracy", cv=kfold)), np.mean(cross_val_score(m3_knn_10, train_imputed, Survival, scoring="accuracy", cv=kfold)), np.mean(cross_val_score(m3_knn_30, train_imputed, Survival, scoring="accuracy", cv=kfold))]) -
Random Forests
m4_rf = RandomForestClassifier(n_estimators=10) accuracy = np.mean(cross_val_score(m4_rf, train_imputed, Survival, scoring="accuracy", cv=kfold)) -
Support Vection Machine(SVM)
m5_svc = SVC(gamma='scale') accuracy = np.mean(cross_val_score(m5_svc, train_imputed, Survival, scoring="accuracy", cv=kfold)) -
Gradient Boosting
m6_gb = XGBClassifier(max_depth=3, n_estimators=300, learning_rate=0.05) accuracy = np.mean(cross_val_score(m6_gb, train_imputed, Survival, scoring="accuracy", cv=kfold))
-
-
각 모델별 예측 정확도는 다음과 같습니다.
‘Gaussian Naive Bayes’: 0.7721988575732848
‘Logistic Regression’: 0.8013621241604418
‘kNN’: 0.7137969995606052
‘Random Forest’: 0.8025171050153789
‘SVM’:0.7171928943569142
‘Gradient Boosting’: 0.8215805661917017
- Gradient Boosting, Random Forests, Logistic Regression, Gaussian Naive Bayes, SVM, kNN 순으로 높은 정확도를 기록하였습니다.
- 성능 좋은 예측 모델을 찾았고, 이제 이 모델을 최적화 하는 것이 남았습니다.
- 최적화를 위해선 어떤 특징들이 더 중요한지 알아내야 합니다.
2. 중요 특징(Feature) 찾기
m6_gb.fit(train_imputed, Survival)
m6_gb.feature_importances_
- 위의 명령어를 통해 가장 성능이 좋은 gb 모델에서의 주요 특징을 찾아보도록 하겠습니다.
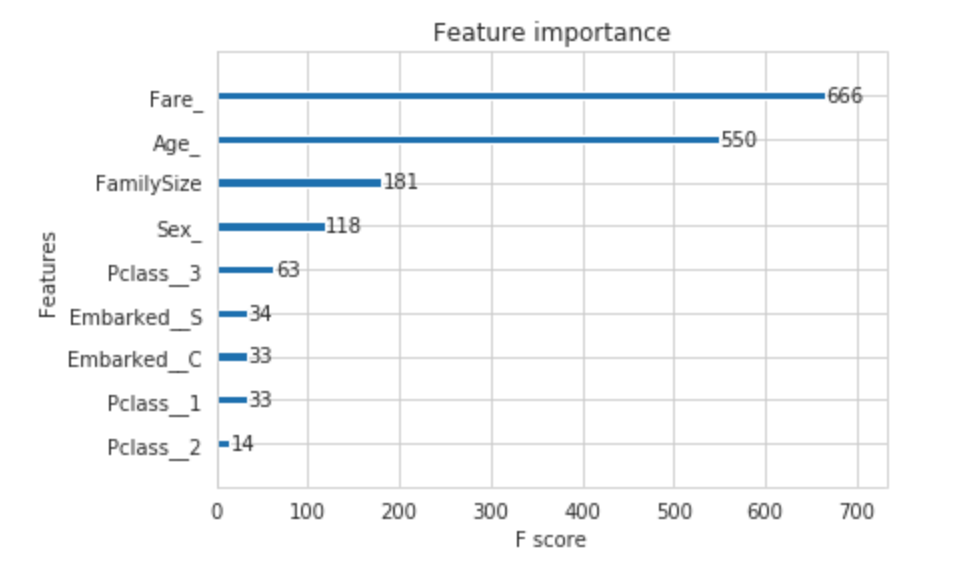
- 위의 그래프에서 볼 수 있듯이 요금(Fare), 나이(Age), 가족 규모(Family Size), 성별(Sex)이 주요한 특징입니다.
3. 최적화 하기
-
위에서 찾은 주요 특징을 이용하여 모델을 최적화 할 것입니다. 여기서 우리는 Grid Search 도구를 이용하여 최적화합니다.
Grid Search 및 최적화 도구에 대한 자세한 정보는 Scikit Learn 최적화 도구에서 확인하세요.
param_grid = {'max_depth': [1, 3, 5, 10, 15], 'n_estimators': [50, 100, 200, 500, 1000], 'learning_rate':[1, 0.1, 0.01, 0.001, 0.0001]} grid = GridSearchCV(XGBClassifier(), param_grid, cv=kfold) grid.fit(train_imputed[['Fare_', 'Age_', 'FamilySize', 'Sex_']], Survival) -
위의 코드로 우리는 최적의 parameter 값을 찾을 수 있습니다.
-
본 예측에서는 learning_rate = 0.01, max_depth = 3, n_estimators = 1000이 최적의 parameter 값입니다. 이를 적용하여 다음과 같이 학습시키도록 합시다.
gb = XGBClassifier(max_depth=3, n_estimators=1000, learning_rate=0.01) accuracy = np.mean(cross_val_score(gb, train_imputed[["Fare_", "Age_", "FamilySize", "Sex_"]], Survival, scoring="accuracy", cv=kfold)) print(accuracy) ------------------------------------------------ 0.8282970309459545 -
최적화 후 나은 정확성을 보여줍니다.
4. 예측하기
-
이제 위에서 만든 모델을 가지고 실제 예측을 해보도록 하겠습니다.
gb.fit(train_imputed[['Fare_', 'Age_', 'FamilySize', 'Sex_']], Survival) predictions = gb.predict(test_imputed[['Fare_', 'Age_', 'FamilySize', 'Sex_']]) result = pd.DataFrame({'PassengerId': test.PassengerId, 'Survived': predictions})
- 예측한 결과는 위와 같습니다!!
마치며..
-
두 번의 포스팅에 걸쳐 Titanic 생존자 예측 시뮬레이션을 해봤습니다.
-
이를 바탕으로 다른 문제에도 도전해보도록 합시다!!
해당 포스팅의 전체 ipython notebook 파일은 다음으로부터 받을 수 있습니다.