간단한 예측을 해보자!! (1)
김승우 책임
간단한 예측을 해보자!!(Titanic 생존자 예측) (1)
저번 포스팅에서 Kaggle에 대해서 간략하게 소개를 했습니다.
이번 포스팅에서는 Kaggle에서 가장 유명한 Titanic 생존자 예측을 해보도록 하겠습니다.
우선 Competitions에서 Titanic을 검색하시고 Titanic: Machine Learning from Disaster Competition에 들어가서 Kernel 항목으로 이동 후 New Kernel을 클릭합니다.
kernel type은 Jupyter Notebook으로 하도록 합시다.
이렇게 Kernel을 생성하면 해당 Competition의 data가 포함되어 가상환경이 설정됩니다. 따로 Data 입력없이 할 수 있어 상당히 유용합니다.
1. 필요 Library 불러오기
- 기본적으로
Numpy,Pandas Library를 사용합니다. 또한 분석과 예측에는Scikit-Learn,XGBoost Library를 사용합니다.
# numpy & pandas
import numpy as np
import pandas as pd
# scikit learn
from sklearn.impute import SimpleImputer
from sklearn.model_selection import cross_val_score, KFold
from sklearn import metrics
2. Data 불러오기
train = pd.read_csv("./input/train.csv")
test = pd.read_csv("./input/test.csv")
sub = pd.read_csv("./input/gender_submission.csv")
- cvs data를
Pandas Library를 이용하여 DataFrame으로 구성함.
3. Dataset 살펴보기
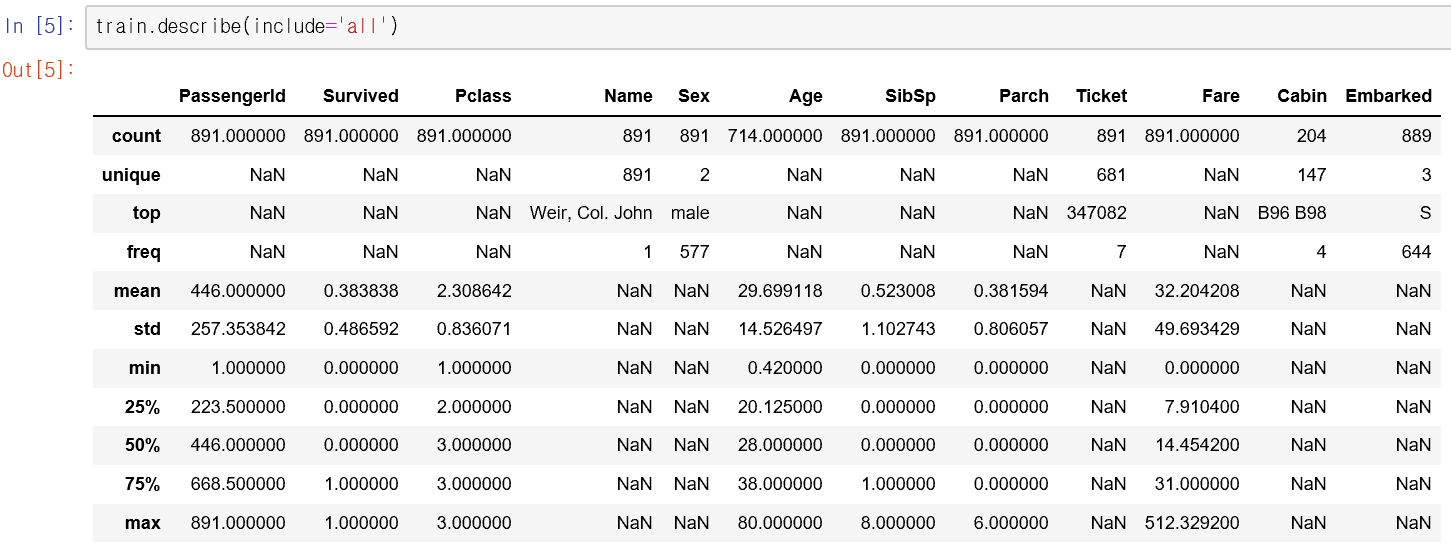
- train data로부터 대략 다음의 정보를 알 수 있습니다.
- 약 38.4%의 승객이 생존함.
- 나이(Age), 선실(Cabin), 승선 항구(Embarked)에 대한 정보가 빠진 승객이 있음.
- 초대받은 사람의 운임은 무료.
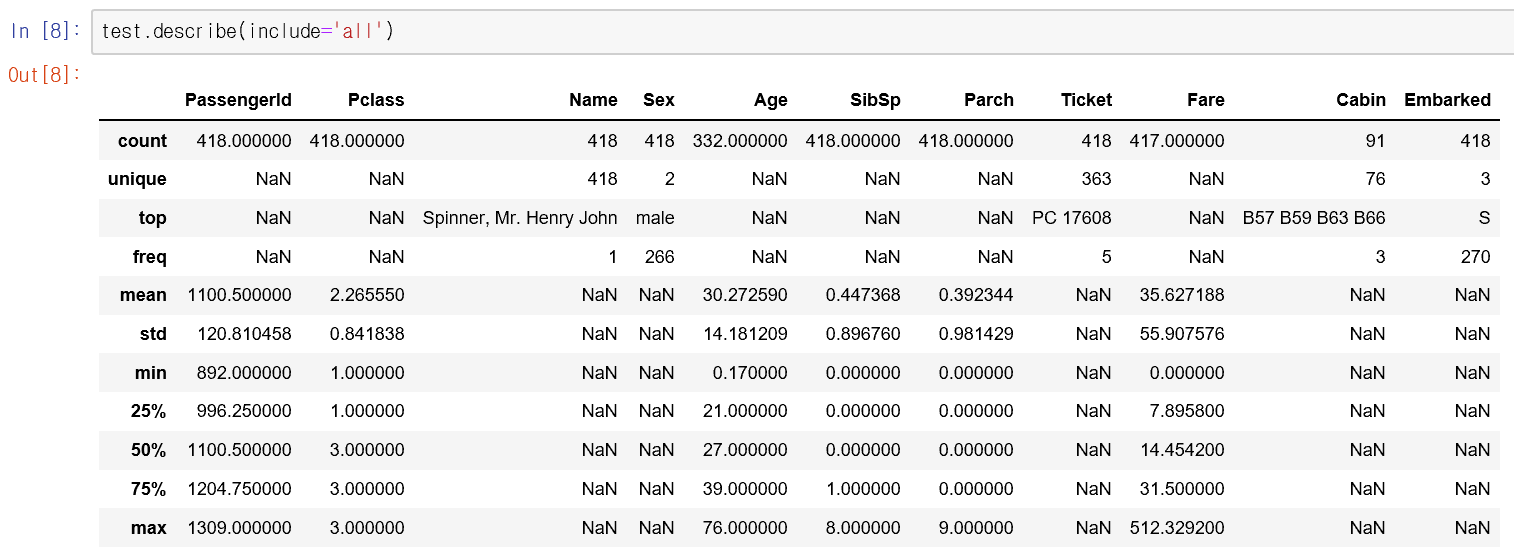
- test data로부터는 다음의 정보를 알 수 있습니다.
- 나이(Age), 운임(Fare), 선실(Cabin)에 대한 정보가 빠진 승객이 있음.
- 초대받은 사람의 운임은 무료.
## 4. EDA(Exploratory data analysis) 하기
-
EDA란 data로부터 형태, 관계를 파악하는 방법입니다. EDA를 통하여 data의 특징을 도출하고 모델링하는 전처리 관계에 해당합니다. -
우선 데이터 사이의 관계를 살펴봅시다.
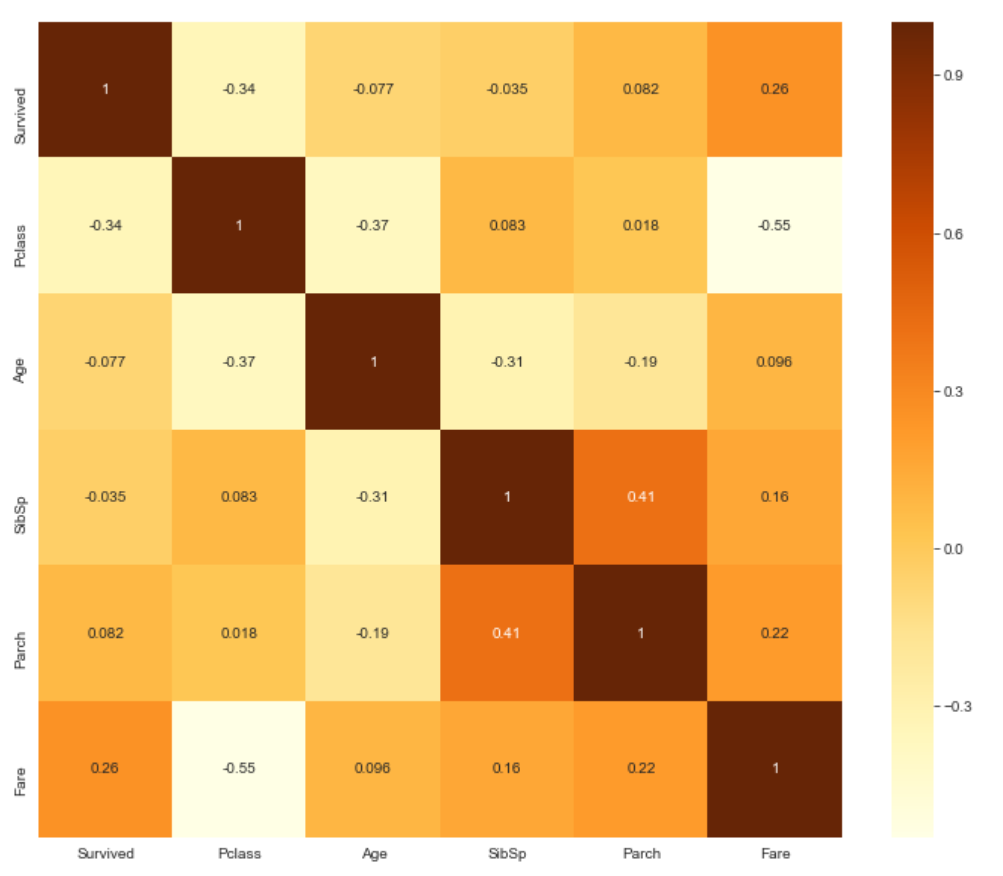
- 위의 그림을 보면 생존 항목은
등급(Pclass)과요금(Fare)의 관계가 있음. - 반면
동승 가족(SibSp, Parch)은 관계가 적음. 나이(Age)와요금(Fare)은등급(Pclass)과 관계가 있음.
- 위의 그림을 보면 생존 항목은
-
생존과 관계가 있는
등급과요금에 대해서 살펴봅시다.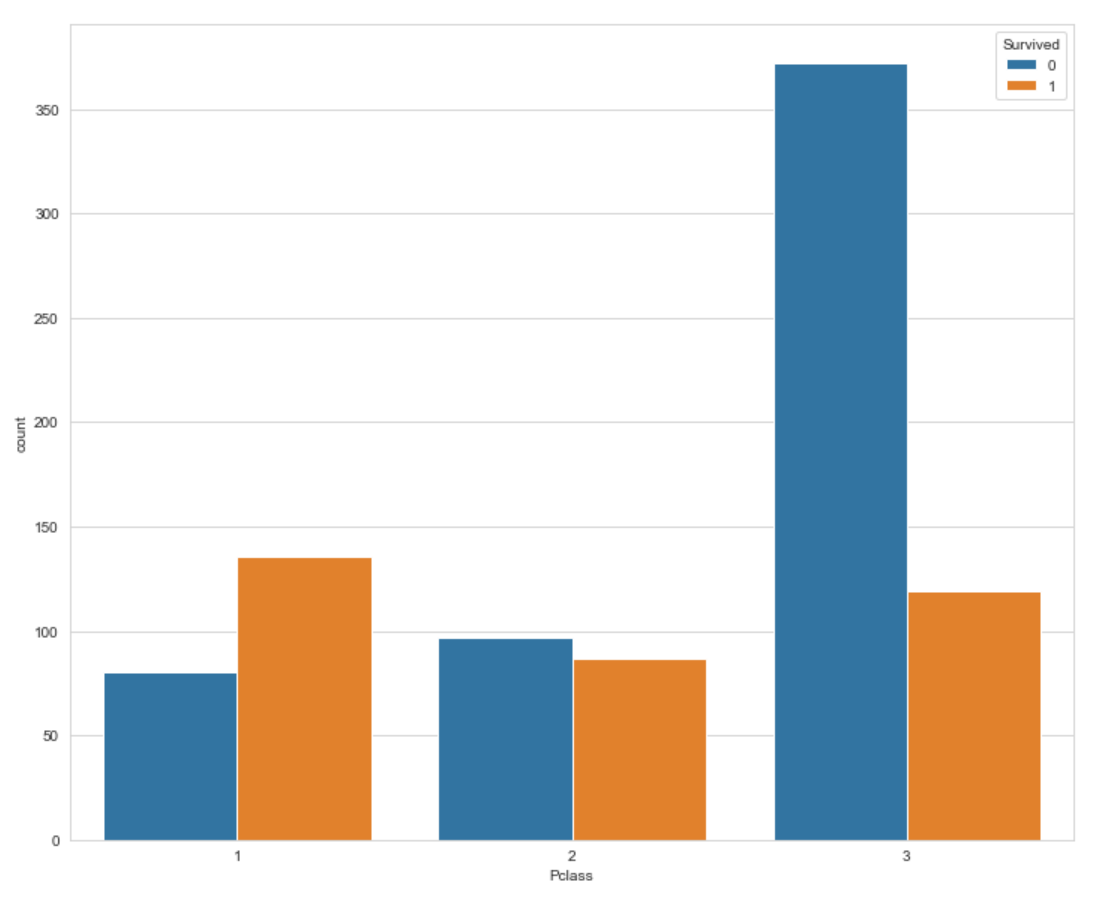
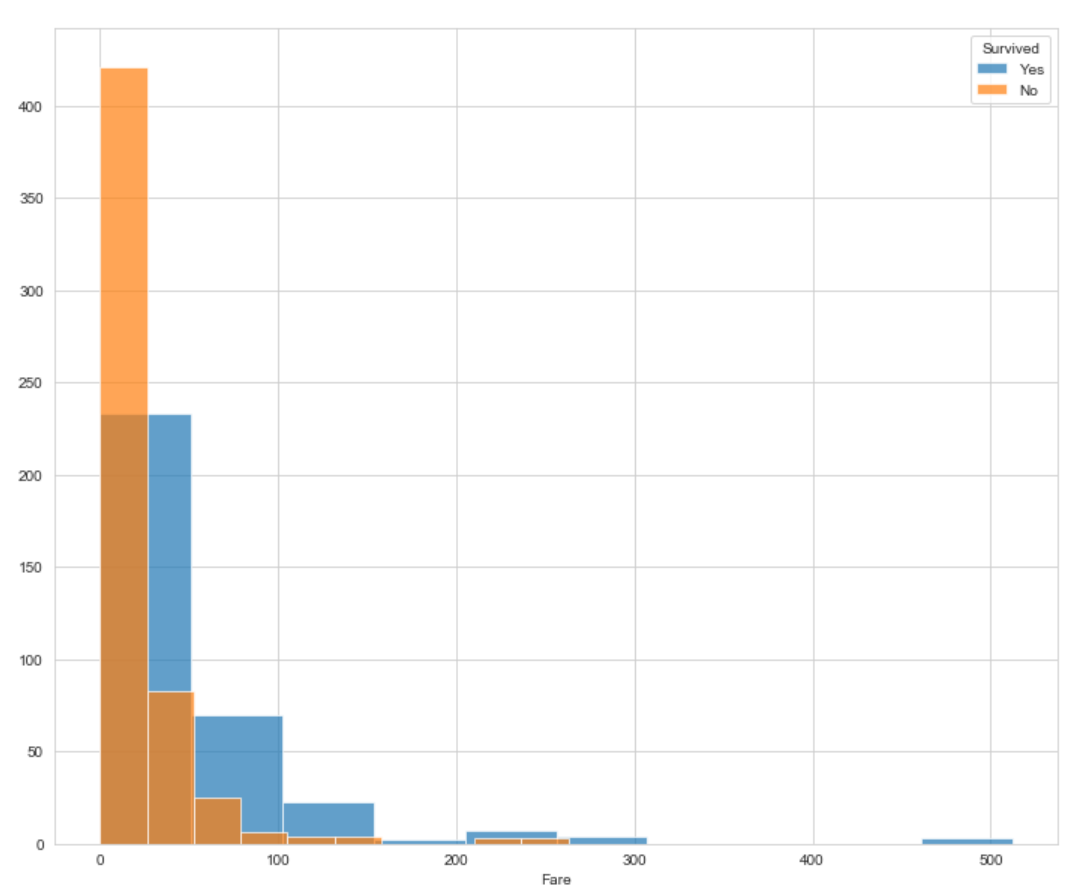
- 1등급 객실 승객이 더 높은 생존률을 보여줍니다.
- 지불 요금이 비쌀수록 더 많이 생존하는 경향을 보여줍니다.
5. Feature Engineering 하기
-
이제 주어진 data에 약간의 변경을 주겠습니다. 이를
Feature Engineering이라고 하는데 주어진 자료에서 새로운 특징을 만들거나 불필요한 항목을 지우는 것을 말합니다. -
승객 ID,선실(Cabin),티켓번호(Ticket) 등의 불필요한 정보를 지웁니다. -
가족 규모,혼자 승선 여부등 새로운 변수값을 만듭니다. -
범주형 항목을 변경
train_after_fe = train.drop(['PassengerId', 'Cabin', 'Ticket'], axis=1)
pclass = pd.get_dummy(train_after_fe['Pclass'], prefix='Pclass_')
Embarked = pd.get_dummy(train_after_fe['Embarked'], prefix='Embarked_')
train_after_fe_dummy = pd.concat([train_after_fe, pclass, Embarked], axis=1)
train_after_fe_dummy = train_after_fe_dummy.drop(['Pclass', 'Sex', 'Embarked'], axis=1)
# tafd = train_after_fe_dummy
tafd['FamilySize'] = tafd.SibSp + tafd.Parch + 1
tafd['Single'] = np.where((tafd.SibSp + tafd.Parch) == 0, 1, 0)
-
이제 새롭게 형성된 feature들의 연관관계를 한 번 봅시다.
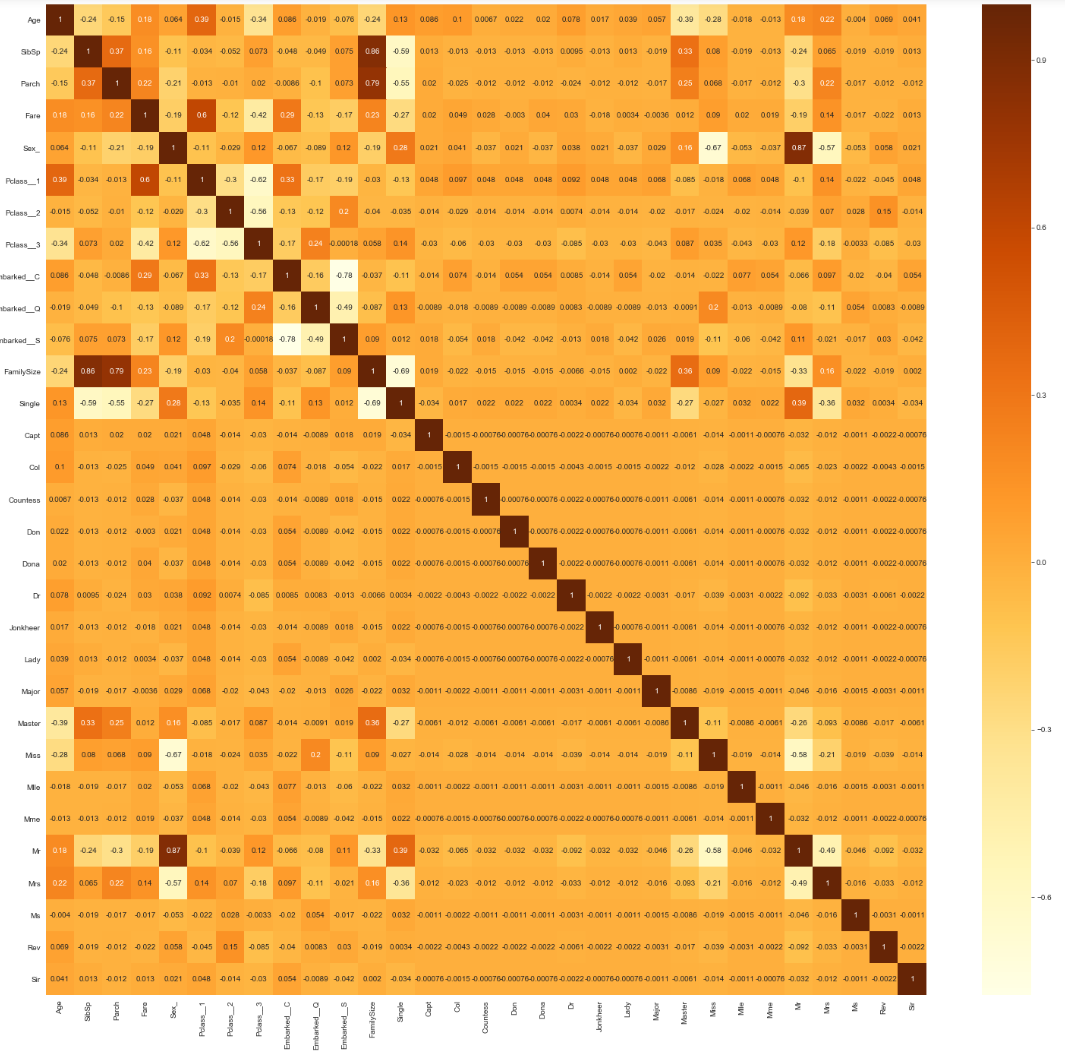
-
모든 항목들의 연관관계를 다 보니 오히려 더 헷갈리는 부분이 많습니다. 약간 항목을 조절해서 보도록 합시다.
new_tafd = tafd.loc[:, 'Age':"Single"]
# SibSp, Parch, Single은 제외함 FamilySize와 직접 연관이 있으므로
new_tafd = new_tafd.drop(['SibSp', 'Parch', 'Single'], axis=1)
plt.figure(figsize=(16, 14))
sns.heatmap(neW_tafd.corr(), annot=True, cmap='Yl0rBr')
-
좀 더 직관적으로 파악할 수 있는 관계도 크기가 되었습니다.
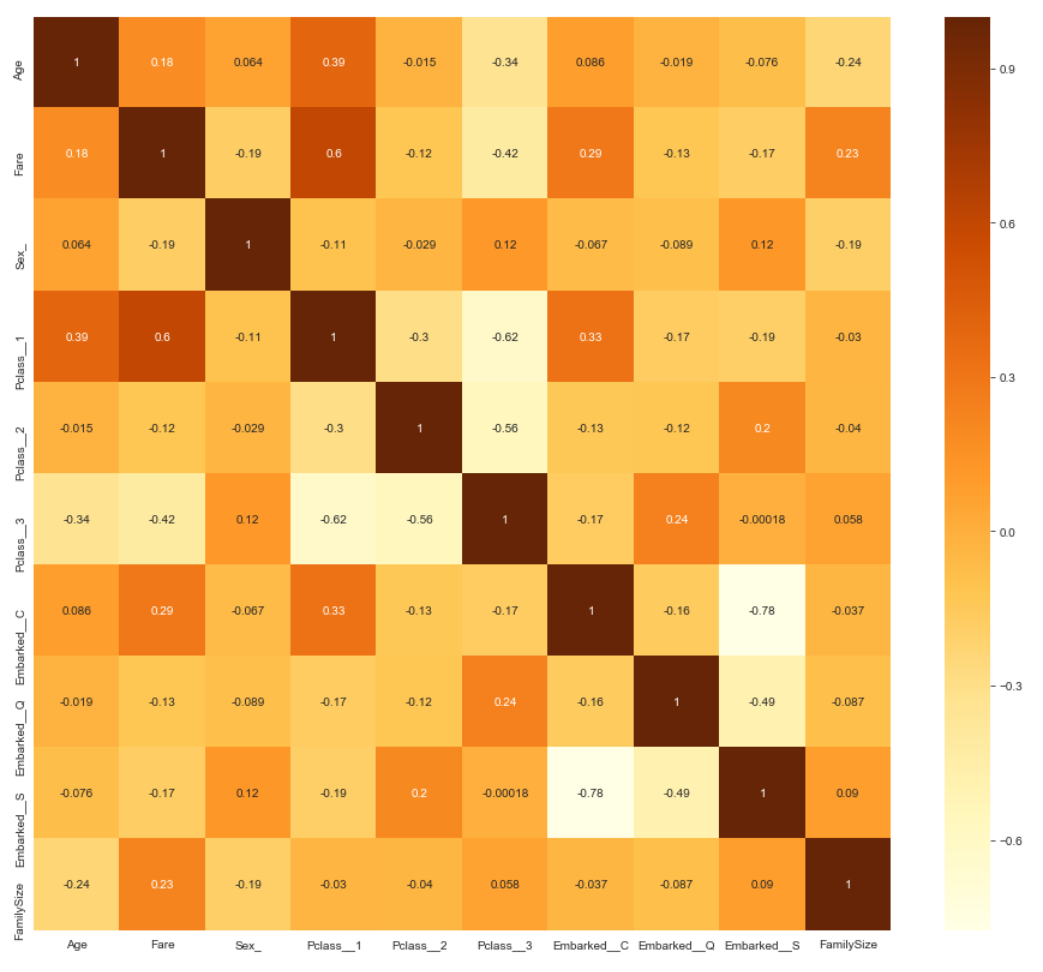
6. 빈 값 채우기
-
나이,요금의 빈 항목을 임의로 채웁니다. Scikit-Learn Imputing을 이용하여 빈 항목을 채웁니다.train_age_imputer = SimpleImputer() train_imputed = train.copy() train_imputed['Age_'] = train_age_imputer.fit_transform(train.iloc[:,0:1]) train_imputed['Fare_'] = train_imputed['Fare'] train_imputed.drop(['Age', 'Fare'], axis=1, inplace=True)
7. 새로운 feature를 포함하여 EDA를 다시 해보기
-
이전엔 없던 feature인
가족 규모에 대한 상관관계에 대해서 알아봅시다.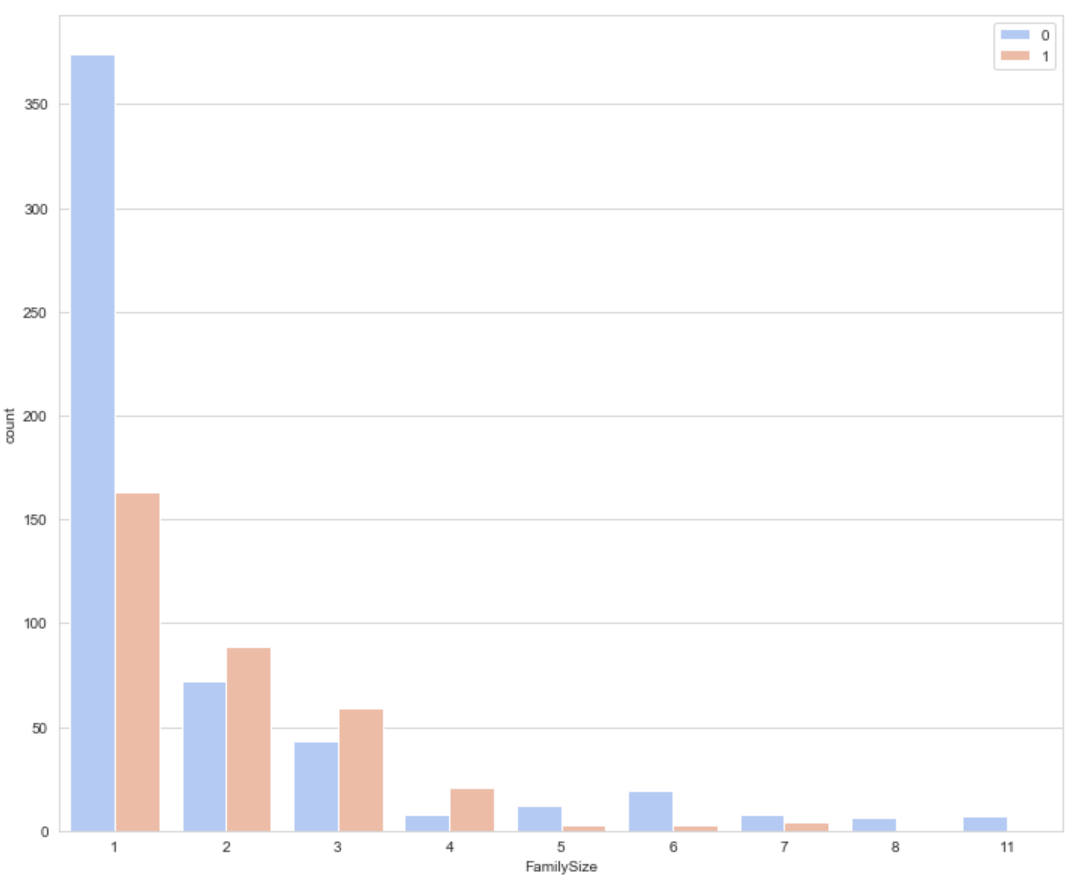
1편을 정리하며…
- 지금까지 데이터 예측을 위한 분석 과정을 같이 해보았습니다. 이 후의 모델링, 학습 및 예측은 2편에서 진행하도록 하겠습니다.