간단한 예측을 해보자!!(3)
김승우 책임
간단한 예측을 해보자!!(심화)-1
지난 예측 블로그에서는 생존 여부만을 판단하는 예측을 해보았습니다. 이번 글에서는 조금 더 현실적인 내용을 다룬 예측을 해보도록 하겠습니다.
dacon.io - baseball prediction
위의 링크는 dacon.io에서 진행했던 2019년 KBO 타자 성적 예측 대회입니다. 현재 제출은 마감된 상태이고 하루 하루 결과들이 업데이트 되고 있습니다.
대회를 요약해서 말씀드리면 기존 타자들의 데이터를 바탕으로 2019년 KBO 타자들의 OPS를 예측하는 대회입니다.
제공 데이터로는 1. 프리시즌 타자 성적, 2. 정규 시즌 타자 성적(통합), 3. 정규 시즌 타자 성적(일별) 입니다.
저희는 제공된 튜토리얼을 바탕으로 한번 예측을 해보도록 하겠습니다.
1. EDA
- 우선 제공된 데이터가 어떤 정보들을 담고 있는지 확인해보도록 합시다.
regular = pd.read_csv("Regular_Season_Batter.csv") regular.columns
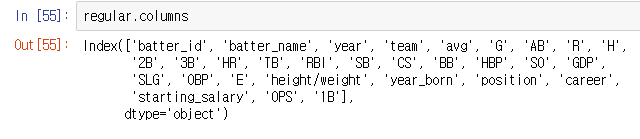
- 위와 같이 타자의 다양한 지표들이 데이터로서 이루어져 있습니다.
- 그럼 이 지표들 가운데 변동성이 큰 지표들을 찾는 작업을 해보겠습니다.
2. 변동성 높은 지표를 찾아보자
-
특정 연도와 그 다음 연도의 지표의 변화량을 바탕으로 변동성을 계산하도록 하겠습니다. ```python #변동성 확인용 Method def plot_variance_feature(var, order): x=[] y=[] #너무 적은 타석수를 가진 연도는 제외 regular1 = regular.loc[regular[‘AB’]>=100]
for name in regular[‘batter_name’].unique(): batter_data = regular1.loc[regular1[‘batter_name’]==name] k = [] for i in batter_data[‘year’].unique(): if (batter_data[‘year’]==i+1).sum() > 0: k.append(i) for i in k: x.append(batter_data.loc[batter_data[‘year’]==i, var].iloc[0]) y.append(batter_data.loc[batter_data[‘year’]==i+1, var].iloc[0]) plt.subplot(6, 3, order) plt.scatter(x, y) plt.title(var) plt.xlabel(‘year’) plt.ylabel(‘year+1’)
#수치 표시 print(var + “:” + str(pd.Series(x).corr(pd.Series(y))))
지표별 변동성 확인
var_list = [‘avg’, ‘AB’, ‘R’, ‘H’, …, ‘GDP’, ‘SLG’, ‘OBP’] plt.figure(figsize=(16, 32)) order = 1 for var in var_list: plot_variance_feature(var, order) order += 1
- 위의 코드를 바탕으로 변동성을 그래프로 보면 다음과 같습니다. 총 18가지의 지표를 계산하였습니다.
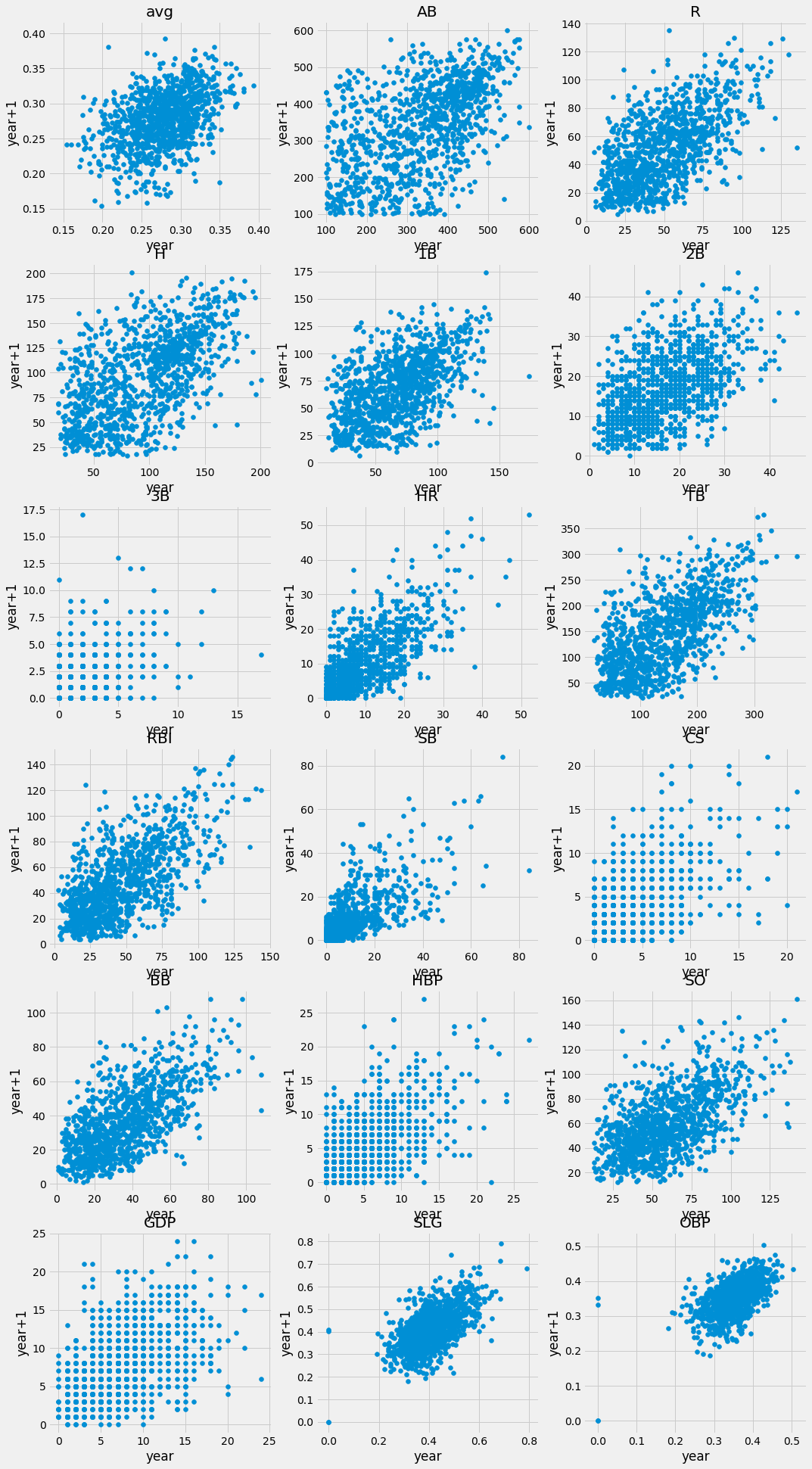
- 수치로 살펴보면 득점(R), 홈런(HR), 타점(RBI), 볼넷(BB), 장타율(SLG) 등은 `0.6` 이상의 계산값을 보여 변동성이 적은 것으로 판단됩니다.
- 반면에 타율(avg), 각종 루타들(1B, 2B, 3B), 출루율(OBP)는 변동성이 높은 것으로 판단됩니다.
#### 3. Feature Engineering
- 위의 EDA 등을 바탕으로 Feature Engineering을 해보도록 합시다.
- 우린 전년도의 성적을 바탕으로 올해의 OPS를 예측하려고 합니다. 하지만 해당 data에는 전년도의 성적은 없습니다.
- 전년도의 성적을 `lag_`var의 이름으로 추가하도록 하겠습니다.
```python
for var in var_list:
lag_1 = []
for i in range(len(regular)):
if len(regular.loc[(regular['batter_name']==regular['batter_name'].iloc[i])&(regular['year']==regular['year'].iloc[i]-1)][j]) == 0:
lag_1.append(np.nan)
else:
lag_1.append(regular.loc[(regular['batter_name']==regular['batter_name'].iloc[i])&(regular['year']==regular['year'].iloc[i]-1)][j].iloc[0])
regular['lag_1_'+var] = lag_1
- 또한 위에서 찾은 변동성이 높은 지표들은 통산 평균을 추가하여 변동성에 대한 보정을 해주도록 합시다.
total_avg_1B = []
total_avg_2B = []
total_avg_3B = []
total_avg = []
total_avg_AB = []
total_avg_OBP = []
for i in range(len(regular)):
df = regular.loc[(regular['batter_name']==regular['batter_name'].iloc[i])&(regular['year']<regular['year'].iloc[i])]
total_avg_1B.append(df['1B'].sum()/df['AB'].sum())
total_avg_2B.append(df['2B'].sum()/df['AB'].sum())
total_avg_3B.append(df['3B'].sum()/df['AB'].sum())
total_avg_AB.append(df['AB'].sum()/len(df))
total_avg_OBP.append(df['OBP'].sum()/len(df))
total_avg.append((df['avg']*df['AB']).sum()/df['AB'].sum())
regular['total_avg_1B'] = total_avg_1B
regular['total_avg_2B'] = total_avg_2B
regular['total_avg_3B'] = total_avg_3B
regular['total_avg'] = total_avg
regular['total_avg_AB'] = total_avg_AB
regular['total_avg_OBP'] = total_avg_OBP
- 이로써 Feature Engineering을 마치고 Training으로 가보도록 하겠습니다.
4. Model Training
-
이번 예측에는
LightGBM을 이용합니다. -
학습에 사용할 지표는
전년도 성적+평균 지표입니다.
input_var = [x for x in regular.columns if ('lag_' in x)|('total_' in x)]
trn_data = lgb.Dataset(train[input_var], label=train['OPS'], weight=train['AB'])
- 위의 값으로 이용해서 학습을 마치고 (대략 10,000회 정도 진행하였습니다.) 모델을 완성합니다.
- 이제 OPS 예측 결과를 알아볼 차례입니다.
predictions = clf.predict(test[input_var])
sub = test[['batter_id', 'batter_name']]
sub['OPS'] = predictions
sub.to_csv("submission.csv", index=False)
- 위를 통해서 예측 결과를 csv 파일로 출력하였습니다.
5. 예측 확인해보기!!
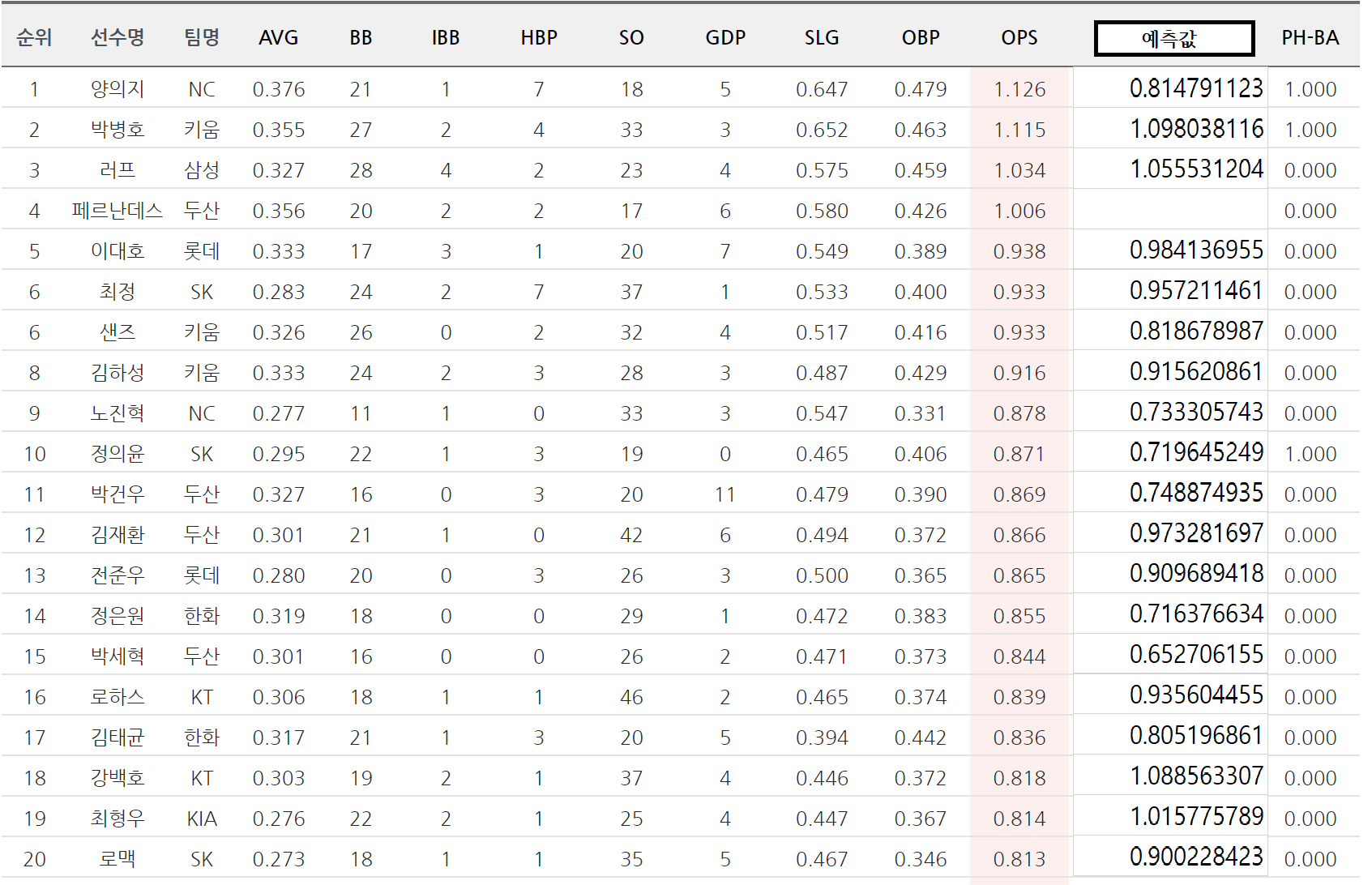
- KBO 자료실에서 가져온 OPS 1~20위 선수들입니다. 옆에 예측값을 추가로 붙여놨는데, 별 차이가 없는 선수가 있는 반면 예측값과 차이가 큰 선수도 있습니다.
- 아직 시즌이 진행 중이며 시즌을 마치면 예측 정확도에 대해서 확실히 알 수 있을 것 같습니다.